Dec 1, 2025
William Kinsman
Rendering FHIR to PDF / HTML
FHIR data is structured, but not human-readable like PDF or HTML. This creates an issue where while FHIR data is better in the new data era, but its code-like structure cannot easily be reviewed by medical experts in common healthcare processes, until now with Tenasol's FHIR rendering solution.
Why FHIR to PDF
FHIR is the most secure, high velocity, detailed medical data format that exists today, having superseded both HL7v2 and HL7v3.
However unlike HL7v2 and HL7v3, which can be rendered to HTML/PDF formats, only Tenasol has created an HL7 FHIR rendering engine to make it human readable for reviewers working on HEDIS, prior authorization, risk, and disability case reviews. These review operations require data to be human readable for legal review purposes.
The HL7 FHIR format therefore faces headwinds, despite its technological advantages, to wide adoption until rendering of FHIR data to HTML/PDF formats is widely accepted and adopted, or policy fully adopts structured data formats. The latter of which is likely long term.
Interoperability and Healthcare Data Quality
Within a hospital system, offices will use the same EMR-native (proprietary) data format. Today, interoperability between healthcare facilities, in the most expansive case, permits transmission of a single patients medical history data in either:
PDF (unstructured data)
HL7v3 CDA (structured and unstructured data)
HL7 FHIR (structured and unstructured data)
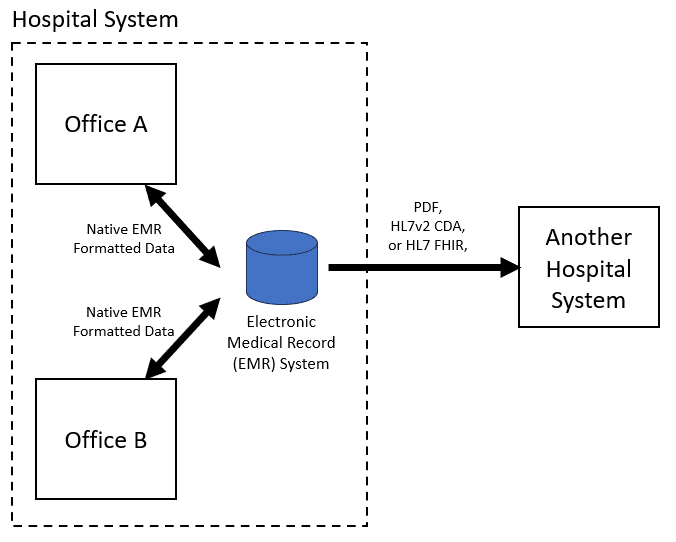
Most operations desire a document that is both readable (like an image) and structured (like code) - which do not exist. The common solution then is to convert one to the other. The problem with this is that whenever data is converted from one format to another, there is loss, whether it is negligible or not. For example, loss occurs when an EMR native format is converted to PDF, CDA or FHIR, by virtue of:
The data field names or locations not being identical between formats, or assumptions made about these fields
Omission of fields where they don't have a location in another format
structured fields being converted to unstructured fields (e.g. CDA -> PDF)
However, the community has deemed these losses negligible in most cases. Examples of this are that EMR-native proprietary formats and HL7 CDA files converted to PDF are accepted as medical evidence by medical examiners and HHS across all disciplines today. There is very little guidance around this for FHIR to PDF.
FHIR and PDF, or, CDA to PDF, or FHIR to PDF
When the government or a health insurer receives data from a source, the ideal scenario is to receive both:
PDF data rendered directly by the EMR installed at the hospital site (for human readable tasks) AND
FHIR data exported directly by the EMR installed at the hospital site (for automated data tasks)
This would result in the best possible rendered data, as well as the best possible and most modern structured data, with the least amount of conversion loss.
Unfortunately, the term "provider abrasion" has come about to describe how the government and insurers can become a nuisance in requesting information too much to the point of impacting healthcare operations, so a facility may not want to go through the trouble of delivering both of these, and only delivers data in whatever format it can on a best-efforts basis. Thus, given that providers are likely only to deliver one format, the options are:
PDF, but then the the payor/govt are do not have structured data (worst but most common)
HL7v3 CDA, but then the payor/govt must convert the data to PDF which results in high data duplication / long PDF records (better option)
HL7 FHIR, but the payor/govt must convert the data to PDF for human readable tasks using the Tenasol FHIR to PDF/HTML conversion process (best option).
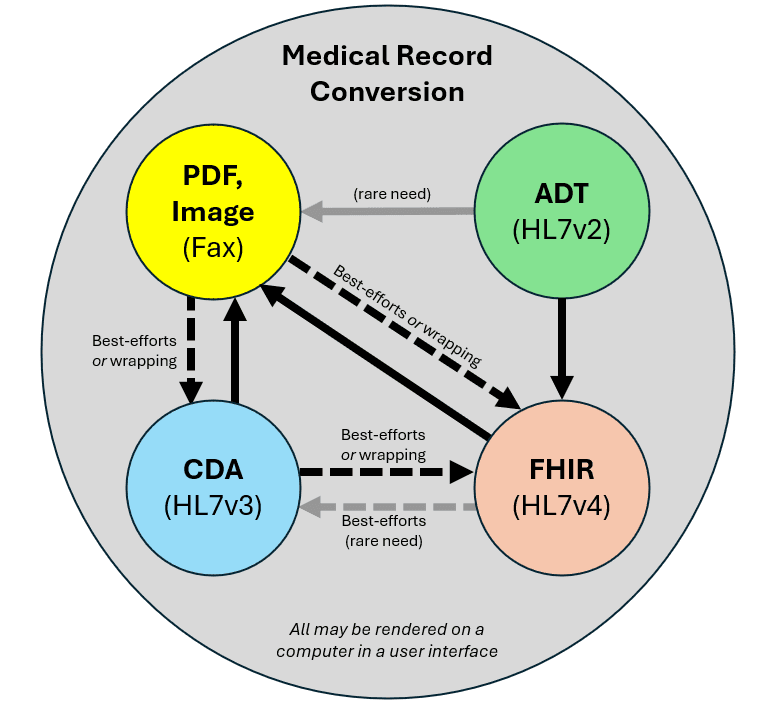
The Best Solution - Tenasol FHIR to PDF / HTML
Tenasol has created a proprietary solution for mapping FHIR data to HTML. This HTML is then converted to PDF to make it human readable in a comfortable manner. This solution:
"One medical record, multiple uses" is preserved.
works across multiple FHIR implementations guides (FHIR IG's)
deduplicates data
permits data to be converted to FHIR from all other formats (X12, RTF, TXT, DOC, DOCX, image, HL7v2, HL7v3), then to HTML/PDF
Permits rendering on websites or within interfaces using HTML
Permits augmented PDF options, such as internal PDF linking and cover page

Conclusion
As healthcare data exchange continues to shift to high-fidelity structured formats, FHIR stands at the center of modern interoperability. Its precision, security, and speed make it the logical successor to HL7v2 and HL7v3, yet its lack of inherent human-readable rendering has slowed practical adoption in real-world review workflows.
Tenasol’s FHIR-to-HTML/PDF rendering solution removes this barrier. By enabling FHIR data to be transformed into clear, deduplicated, human-readable documents—while preserving the structured data underneath—Tenasol provides the missing bridge between next-generation data formats and the operational realities of healthcare review. Providers can continue submitting a single dataset with minimal abrasion, while payers gain modern structured data and compliant human-readable evidence.
As policy trends increasingly favor digital submissions, solutions that unify structured and human-readable outputs will become essential. Tenasol’s approach positions FHIR not just as the future of interoperability, but as a format that can finally meet today’s operational, legal, and clinical needs.
If you are interested in this service, contact us.
You can also see our interactive FHIR viewer here.
FHIR data is structured, but not human-readable like PDF or HTML. This creates an issue where while FHIR data is better in the new data era, but its code-like structure cannot easily be reviewed by medical experts in common healthcare processes, until now with Tenasol's FHIR rendering solution.
Why FHIR to PDF
FHIR is the most secure, high velocity, detailed medical data format that exists today, having superseded both HL7v2 and HL7v3.
However unlike HL7v2 and HL7v3, which can be rendered to HTML/PDF formats, only Tenasol has created an HL7 FHIR rendering engine to make it human readable for reviewers working on HEDIS, prior authorization, risk, and disability case reviews. These review operations require data to be human readable for legal review purposes.
The HL7 FHIR format therefore faces headwinds, despite its technological advantages, to wide adoption until rendering of FHIR data to HTML/PDF formats is widely accepted and adopted, or policy fully adopts structured data formats. The latter of which is likely long term.
Interoperability and Healthcare Data Quality
Within a hospital system, offices will use the same EMR-native (proprietary) data format. Today, interoperability between healthcare facilities, in the most expansive case, permits transmission of a single patients medical history data in either:
PDF (unstructured data)
HL7v3 CDA (structured and unstructured data)
HL7 FHIR (structured and unstructured data)
Most operations desire a document that is both readable (like an image) and structured (like code) - which do not exist. The common solution then is to convert one to the other. The problem with this is that whenever data is converted from one format to another, there is loss, whether it is negligible or not. For example, loss occurs when an EMR native format is converted to PDF, CDA or FHIR, by virtue of:
The data field names or locations not being identical between formats, or assumptions made about these fields
Omission of fields where they don't have a location in another format
structured fields being converted to unstructured fields (e.g. CDA -> PDF)
However, the community has deemed these losses negligible in most cases. Examples of this are that EMR-native proprietary formats and HL7 CDA files converted to PDF are accepted as medical evidence by medical examiners and HHS across all disciplines today. There is very little guidance around this for FHIR to PDF.
FHIR and PDF, or, CDA to PDF, or FHIR to PDF
When the government or a health insurer receives data from a source, the ideal scenario is to receive both:
PDF data rendered directly by the EMR installed at the hospital site (for human readable tasks) AND
FHIR data exported directly by the EMR installed at the hospital site (for automated data tasks)
This would result in the best possible rendered data, as well as the best possible and most modern structured data, with the least amount of conversion loss.
Unfortunately, the term "provider abrasion" has come about to describe how the government and insurers can become a nuisance in requesting information too much to the point of impacting healthcare operations, so a facility may not want to go through the trouble of delivering both of these, and only delivers data in whatever format it can on a best-efforts basis. Thus, given that providers are likely only to deliver one format, the options are:
PDF, but then the the payor/govt are do not have structured data (worst but most common)
HL7v3 CDA, but then the payor/govt must convert the data to PDF which results in high data duplication / long PDF records (better option)
HL7 FHIR, but the payor/govt must convert the data to PDF for human readable tasks using the Tenasol FHIR to PDF/HTML conversion process (best option).
The Best Solution - Tenasol FHIR to PDF / HTML
Tenasol has created a proprietary solution for mapping FHIR data to HTML. This HTML is then converted to PDF to make it human readable in a comfortable manner. This solution:
"One medical record, multiple uses" is preserved.
works across multiple FHIR implementations guides (FHIR IG's)
deduplicates data
permits data to be converted to FHIR from all other formats (X12, RTF, TXT, DOC, DOCX, image, HL7v2, HL7v3), then to HTML/PDF
Permits rendering on websites or within interfaces using HTML
Permits augmented PDF options, such as internal PDF linking and cover page
Conclusion
As healthcare data exchange continues to shift to high-fidelity structured formats, FHIR stands at the center of modern interoperability. Its precision, security, and speed make it the logical successor to HL7v2 and HL7v3, yet its lack of inherent human-readable rendering has slowed practical adoption in real-world review workflows.
Tenasol’s FHIR-to-HTML/PDF rendering solution removes this barrier. By enabling FHIR data to be transformed into clear, deduplicated, human-readable documents—while preserving the structured data underneath—Tenasol provides the missing bridge between next-generation data formats and the operational realities of healthcare review. Providers can continue submitting a single dataset with minimal abrasion, while payers gain modern structured data and compliant human-readable evidence.
As policy trends increasingly favor digital submissions, solutions that unify structured and human-readable outputs will become essential. Tenasol’s approach positions FHIR not just as the future of interoperability, but as a format that can finally meet today’s operational, legal, and clinical needs.
If you are interested in this service, contact us.
You can also see our interactive FHIR viewer here.
FHIR data is structured, but not human-readable like PDF or HTML. This creates an issue where while FHIR data is better in the new data era, but its code-like structure cannot easily be reviewed by medical experts in common healthcare processes, until now with Tenasol's FHIR rendering solution.
Why FHIR to PDF
FHIR is the most secure, high velocity, detailed medical data format that exists today, having superseded both HL7v2 and HL7v3.
However unlike HL7v2 and HL7v3, which can be rendered to HTML/PDF formats, only Tenasol has created an HL7 FHIR rendering engine to make it human readable for reviewers working on HEDIS, prior authorization, risk, and disability case reviews. These review operations require data to be human readable for legal review purposes.
The HL7 FHIR format therefore faces headwinds, despite its technological advantages, to wide adoption until rendering of FHIR data to HTML/PDF formats is widely accepted and adopted, or policy fully adopts structured data formats. The latter of which is likely long term.
Interoperability and Healthcare Data Quality
Within a hospital system, offices will use the same EMR-native (proprietary) data format. Today, interoperability between healthcare facilities, in the most expansive case, permits transmission of a single patients medical history data in either:
PDF (unstructured data)
HL7v3 CDA (structured and unstructured data)
HL7 FHIR (structured and unstructured data)
Most operations desire a document that is both readable (like an image) and structured (like code) - which do not exist. The common solution then is to convert one to the other. The problem with this is that whenever data is converted from one format to another, there is loss, whether it is negligible or not. For example, loss occurs when an EMR native format is converted to PDF, CDA or FHIR, by virtue of:
The data field names or locations not being identical between formats, or assumptions made about these fields
Omission of fields where they don't have a location in another format
structured fields being converted to unstructured fields (e.g. CDA -> PDF)
However, the community has deemed these losses negligible in most cases. Examples of this are that EMR-native proprietary formats and HL7 CDA files converted to PDF are accepted as medical evidence by medical examiners and HHS across all disciplines today. There is very little guidance around this for FHIR to PDF.
FHIR and PDF, or, CDA to PDF, or FHIR to PDF
When the government or a health insurer receives data from a source, the ideal scenario is to receive both:
PDF data rendered directly by the EMR installed at the hospital site (for human readable tasks) AND
FHIR data exported directly by the EMR installed at the hospital site (for automated data tasks)
This would result in the best possible rendered data, as well as the best possible and most modern structured data, with the least amount of conversion loss.
Unfortunately, the term "provider abrasion" has come about to describe how the government and insurers can become a nuisance in requesting information too much to the point of impacting healthcare operations, so a facility may not want to go through the trouble of delivering both of these, and only delivers data in whatever format it can on a best-efforts basis. Thus, given that providers are likely only to deliver one format, the options are:
PDF, but then the the payor/govt are do not have structured data (worst but most common)
HL7v3 CDA, but then the payor/govt must convert the data to PDF which results in high data duplication / long PDF records (better option)
HL7 FHIR, but the payor/govt must convert the data to PDF for human readable tasks using the Tenasol FHIR to PDF/HTML conversion process (best option).
The Best Solution - Tenasol FHIR to PDF / HTML
Tenasol has created a proprietary solution for mapping FHIR data to HTML. This HTML is then converted to PDF to make it human readable in a comfortable manner. This solution:
"One medical record, multiple uses" is preserved.
works across multiple FHIR implementations guides (FHIR IG's)
deduplicates data
permits data to be converted to FHIR from all other formats (X12, RTF, TXT, DOC, DOCX, image, HL7v2, HL7v3), then to HTML/PDF
Permits rendering on websites or within interfaces using HTML
Permits augmented PDF options, such as internal PDF linking and cover page
Conclusion
As healthcare data exchange continues to shift to high-fidelity structured formats, FHIR stands at the center of modern interoperability. Its precision, security, and speed make it the logical successor to HL7v2 and HL7v3, yet its lack of inherent human-readable rendering has slowed practical adoption in real-world review workflows.
Tenasol’s FHIR-to-HTML/PDF rendering solution removes this barrier. By enabling FHIR data to be transformed into clear, deduplicated, human-readable documents—while preserving the structured data underneath—Tenasol provides the missing bridge between next-generation data formats and the operational realities of healthcare review. Providers can continue submitting a single dataset with minimal abrasion, while payers gain modern structured data and compliant human-readable evidence.
As policy trends increasingly favor digital submissions, solutions that unify structured and human-readable outputs will become essential. Tenasol’s approach positions FHIR not just as the future of interoperability, but as a format that can finally meet today’s operational, legal, and clinical needs.
If you are interested in this service, contact us.
You can also see our interactive FHIR viewer here.




GET STARTED NOW
Leverage the Power of AI with Tenasol Today!

Powered by AI,
Purpose Built for Healthcare

Contact Information
2461 Eisenhower Avenue, 2nd Floor
Alexandria, VA 22314
Phone: (202) 888-1757
© 2026 Tenasol. All rights reserved.



Disclaimer:
The information and materials on this website are provided for general informational purposes only and are subject to change without notice. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability of the website or its content. Any reliance you place on such information is strictly at your own risk. We are not responsible for, and do not necessarily endorse, the content of any third-party websites linked from this site. All product names, logos, and brands are property of their respective owners.
Powered by AI,
Purpose Built for Healthcare
Contact Information
2461 Eisenhower Avenue, 2nd Floor
Alexandria, VA 22314
Phone: (202) 888-1757
© 2026 Tenasol. All rights reserved.
Disclaimer:
The information and materials on this website are provided for general informational purposes only and are subject to change without notice. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability of the website or its content. Any reliance you place on such information is strictly at your own risk. We are not responsible for, and do not necessarily endorse, the content of any third-party websites linked from this site. All product names, logos, and brands are property of their respective owners.
Powered by AI,
Purpose Built for Healthcare
Contact Information
2461 Eisenhower Avenue, 2nd Floor
Alexandria, VA 22314
Phone: (202) 888-1757
© 2026 Tenasol. All rights reserved.
Disclaimer:
The information and materials on this website are provided for general informational purposes only and are subject to change without notice. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability of the website or its content. Any reliance you place on such information is strictly at your own risk. We are not responsible for, and do not necessarily endorse, the content of any third-party websites linked from this site. All product names, logos, and brands are property of their respective owners.