May 14, 2026
Teddy Gedamu
CDA to FHIR Transformation: What Data Are You Missing?
In healthcare, modern digital transformation initiatives are built on FHIR. Despite this, most healthcare organizations operate on a data continuum, processing a myriad of formats from various sources. While the mix will evolve, fragmentation is a feature of health data that will remain into perpetuity. As healthcare enters this new era, enabling a complete transformation of all available data across the enterprise will be critical to success. In this blog, we use CDA as an example to highlight common approaches and challenges used for healthcare data transformation and why this capability is essential for any health plan's long-term data strategy.
Redefining Interoperability
Most large healthcare organizations collect data in a variety of ways. Interoperability has long been narrowly defined around transitioning collection away from manual to digital acquisition methods. Current policies, like CMS-0057, are shifting the focus away from solely a data exchange paradigm to large-scale transformation of legacy processes such as prior authorization and quality reporting. Success in these programs requires not just movement of data, but sophisticated processing, extraction, transformation, and other critical capabilities. For interoperability to be successful, it must reexamine its role in the data stack beyond “connecting data”.
Current Data Transformation Capabilities
HL7 v3 CDA, the most widely exchanged health data standard via national, regional, and private EHR networks, is a great example of the current state of data transformation in healthcare.
The standard approach for CDA extraction is by leveraging XPath, where specific data elements within the XML hierarchy (e.g., medications, allergies, etc.) are defined in advance of processing and extraction. The CMS Blue Button app is a great example of this. Once data has been extracted and normalized, it is then mapped to its destination format. For FHIR transformations, numerous mapping guides exist depending on which version and/or use case you are pursuing.
The main challenge with this approach is that it assumes data is consistently structured in the same way across various source systems that produce it. Anyone who has implemented this scale understands this is far from reality. The standards for CDA provide too much variation, which is why scaling such an approach beyond a single data source or EHR system is so difficult, resulting in incompleteness, quality issues, or delays due to significant customization.
The Tenasol Approach: A Medical Record Search Engine
At Tenasol, we’ve built our data platform to be agnostic of any single data format or structure. We expect that data will be inconsistently formatted, and our platform scales to process all data without significant implementation needed to accommodate additional evidence sources. Whether CDA, ADT, images, or FHIR data, our platform operates much more like a medical record search engine, where we crawl the entire contents of a health record, searching for over 4 million codes, terminologies, and health measure evidence sets.
For CDA processing, this means traversing the entire tree, including narrative text, attachments, base-64 encoded data, and parent/child files. Whether processing data from a single EHR or 100 sources simultaneously, the full extract is available on demand and without any one-off implementation or engineering. Recently, our team evaluated several leading CDA to FHIR transformation platforms to compare our solution, and the results were striking. We reviewed two (2) separate examples, each scenario leveraging progressively more complex data to test the limits of existing systems. Using the same de-identified file(s) across each system, Tenasol consistently exceeded performance in terms of information density, conformance, and provenance/traceability.
Sample #1 CDA R2
Tenasol | Vendor 2 | Vendor 3 |
 |
 | 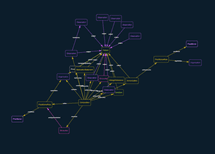 |
Key Findings from Sample 1
Up to 3x Data Captured: During the extraction and conversion process. Tenasol extracted the 79 entities, compared with Vendor 2 (42) and Vendor 3 (23). Vendor 3 demonstrates the most data loss as several concepts were lost in the conversion to FHIR, including: Encounters, Procedures, Medications, and others.
Improved Structure and Validation: Referential integrity is an issue for Vendor 2 as several resources have invalid references to specific resources (e.g., Diagnostic report, practitioner, and patient). Tenasol’s output conforms to the expected FHIR output and passed validation with no issues.
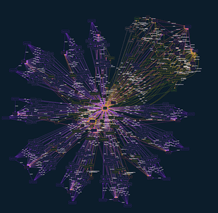
Sample #2: CDA R2, X12, ADT, and PDF Record
Tenasol | Vendor 2 | Vendor 3 |
 |
N/A |
N/A
|
Key Findings from Sample 2
(Note: Comparisons for Vendor 2 and 3 were not available as they could not process the input formats in scope. Additionally, we could not identify alternative systems capable of processing this diversity of data for comparison purposes.)
Scalability – Tenasol demonstrated the ability to transform multiple disparate data formats as listed above (ADT, CDA, PDF, X12) from varying EMR/source systems.
Information Gain – In addition to sample 1, a total of 319 concepts were extracted. We now see additional data included in the FHIR bundle, unique to these additional data types, including Claim, Coverage, Device, EOB.
Plug and Play – This output demonstrates the scalability of information extraction leveraging the “search” methodology described above. In addition to supporting multiple input formats, Tenasol’s platform can ingest data from newly available EMRs and perform transformation immediately, without implementation or customization.
Conclusion
Success in the future of data-driven, AI-enabled healthcare requires a true data foundation. As FHIR becomes more ubiquitous, data transformation capabilities will prove to be a critical component of the interoperability stack. As we’ve seen from the examples above, stakeholders should carefully consider whether legacy approaches to enabling this transformation are well-suited to support their long-term data strategy.
Poor Program Performance: Omitting critical evidence, in the FHIR transformation process, including Medications, Procedures, Conditions, and other items, can greatly impact performance on critical quality measures (e.g., COL, BCS), prior authorization decision accuracy, and more.
Data quality monitoring: elevating data quality is only possible when systems are capable of fully analyzing its contents. By fully extracting all data during the conversion process, you can begin evaluating structure, duplication, and terminology (among other things) in real time and build data quality performance incentives into your interoperability agreements.
Compliance Mitigation: Operating on incomplete or missing data exposes organizations to audit and compliance risk. Ensuring full traceability, including context for extracted data and provenance to link source data, and minimizing audit risk
As we’ve seen, healthcare stakeholders should carefully consider whether legacy approaches to enabling this transformation are well-suited to support their long-term data strategy for today and beyond. At Tenasol, complete data extraction powers our platform, unlocking the full potential of your most valuable and useful asset – your data.
In healthcare, modern digital transformation initiatives are built on FHIR. Despite this, most healthcare organizations operate on a data continuum, processing a myriad of formats from various sources. While the mix will evolve, fragmentation is a feature of health data that will remain into perpetuity. As healthcare enters this new era, enabling a complete transformation of all available data across the enterprise will be critical to success. In this blog, we use CDA as an example to highlight common approaches and challenges used for healthcare data transformation and why this capability is essential for any health plan's long-term data strategy.
Redefining Interoperability
Most large healthcare organizations collect data in a variety of ways. Interoperability has long been narrowly defined around transitioning collection away from manual to digital acquisition methods. Current policies, like CMS-0057, are shifting the focus away from solely a data exchange paradigm to large-scale transformation of legacy processes such as prior authorization and quality reporting. Success in these programs requires not just movement of data, but sophisticated processing, extraction, transformation, and other critical capabilities. For interoperability to be successful, it must reexamine its role in the data stack beyond “connecting data”.
Current Data Transformation Capabilities
HL7 v3 CDA, the most widely exchanged health data standard via national, regional, and private EHR networks, is a great example of the current state of data transformation in healthcare.
The standard approach for CDA extraction is by leveraging XPath, where specific data elements within the XML hierarchy (e.g., medications, allergies, etc.) are defined in advance of processing and extraction. The CMS Blue Button app is a great example of this. Once data has been extracted and normalized, it is then mapped to its destination format. For FHIR transformations, numerous mapping guides exist depending on which version and/or use case you are pursuing.
The main challenge with this approach is that it assumes data is consistently structured in the same way across various source systems that produce it. Anyone who has implemented this scale understands this is far from reality. The standards for CDA provide too much variation, which is why scaling such an approach beyond a single data source or EHR system is so difficult, resulting in incompleteness, quality issues, or delays due to significant customization.
The Tenasol Approach: A Medical Record Search Engine
At Tenasol, we’ve built our data platform to be agnostic of any single data format or structure. We expect that data will be inconsistently formatted, and our platform scales to process all data without significant implementation needed to accommodate additional evidence sources. Whether CDA, ADT, images, or FHIR data, our platform operates much more like a medical record search engine, where we crawl the entire contents of a health record, searching for over 4 million codes, terminologies, and health measure evidence sets.
For CDA processing, this means traversing the entire tree, including narrative text, attachments, base-64 encoded data, and parent/child files. Whether processing data from a single EHR or 100 sources simultaneously, the full extract is available on demand and without any one-off implementation or engineering. Recently, our team evaluated several leading CDA to FHIR transformation platforms to compare our solution, and the results were striking. We reviewed two (2) separate examples, each scenario leveraging progressively more complex data to test the limits of existing systems. Using the same de-identified file(s) across each system, Tenasol consistently exceeded performance in terms of information density, conformance, and provenance/traceability.
Sample #1 CDA R2
Tenasol | Vendor 2 | Vendor 3 |
|
| |
Key Findings from Sample 1
Up to 3x Data Captured: During the extraction and conversion process. Tenasol extracted the 79 entities, compared with Vendor 2 (42) and Vendor 3 (23). Vendor 3 demonstrates the most data loss as several concepts were lost in the conversion to FHIR, including: Encounters, Procedures, Medications, and others.
Improved Structure and Validation: Referential integrity is an issue for Vendor 2 as several resources have invalid references to specific resources (e.g., Diagnostic report, practitioner, and patient). Tenasol’s output conforms to the expected FHIR output and passed validation with no issues.
Sample #2: CDA R2, X12, ADT, and PDF Record
Tenasol | Vendor 2 | Vendor 3 |
|
N/A |
N/A
|
Key Findings from Sample 2
(Note: Comparisons for Vendor 2 and 3 were not available as they could not process the input formats in scope. Additionally, we could not identify alternative systems capable of processing this diversity of data for comparison purposes.)
Scalability – Tenasol demonstrated the ability to transform multiple disparate data formats as listed above (ADT, CDA, PDF, X12) from varying EMR/source systems.
Information Gain – In addition to sample 1, a total of 319 concepts were extracted. We now see additional data included in the FHIR bundle, unique to these additional data types, including Claim, Coverage, Device, EOB.
Plug and Play – This output demonstrates the scalability of information extraction leveraging the “search” methodology described above. In addition to supporting multiple input formats, Tenasol’s platform can ingest data from newly available EMRs and perform transformation immediately, without implementation or customization.
Conclusion
Success in the future of data-driven, AI-enabled healthcare requires a true data foundation. As FHIR becomes more ubiquitous, data transformation capabilities will prove to be a critical component of the interoperability stack. As we’ve seen from the examples above, stakeholders should carefully consider whether legacy approaches to enabling this transformation are well-suited to support their long-term data strategy.
Poor Program Performance: Omitting critical evidence, in the FHIR transformation process, including Medications, Procedures, Conditions, and other items, can greatly impact performance on critical quality measures (e.g., COL, BCS), prior authorization decision accuracy, and more.
Data quality monitoring: elevating data quality is only possible when systems are capable of fully analyzing its contents. By fully extracting all data during the conversion process, you can begin evaluating structure, duplication, and terminology (among other things) in real time and build data quality performance incentives into your interoperability agreements.
Compliance Mitigation: Operating on incomplete or missing data exposes organizations to audit and compliance risk. Ensuring full traceability, including context for extracted data and provenance to link source data, and minimizing audit risk
As we’ve seen, healthcare stakeholders should carefully consider whether legacy approaches to enabling this transformation are well-suited to support their long-term data strategy for today and beyond. At Tenasol, complete data extraction powers our platform, unlocking the full potential of your most valuable and useful asset – your data.
In healthcare, modern digital transformation initiatives are built on FHIR. Despite this, most healthcare organizations operate on a data continuum, processing a myriad of formats from various sources. While the mix will evolve, fragmentation is a feature of health data that will remain into perpetuity. As healthcare enters this new era, enabling a complete transformation of all available data across the enterprise will be critical to success. In this blog, we use CDA as an example to highlight common approaches and challenges used for healthcare data transformation and why this capability is essential for any health plan's long-term data strategy.
Redefining Interoperability
Most large healthcare organizations collect data in a variety of ways. Interoperability has long been narrowly defined around transitioning collection away from manual to digital acquisition methods. Current policies, like CMS-0057, are shifting the focus away from solely a data exchange paradigm to large-scale transformation of legacy processes such as prior authorization and quality reporting. Success in these programs requires not just movement of data, but sophisticated processing, extraction, transformation, and other critical capabilities. For interoperability to be successful, it must reexamine its role in the data stack beyond “connecting data”.
Current Data Transformation Capabilities
HL7 v3 CDA, the most widely exchanged health data standard via national, regional, and private EHR networks, is a great example of the current state of data transformation in healthcare.
The standard approach for CDA extraction is by leveraging XPath, where specific data elements within the XML hierarchy (e.g., medications, allergies, etc.) are defined in advance of processing and extraction. The CMS Blue Button app is a great example of this. Once data has been extracted and normalized, it is then mapped to its destination format. For FHIR transformations, numerous mapping guides exist depending on which version and/or use case you are pursuing.
The main challenge with this approach is that it assumes data is consistently structured in the same way across various source systems that produce it. Anyone who has implemented this scale understands this is far from reality. The standards for CDA provide too much variation, which is why scaling such an approach beyond a single data source or EHR system is so difficult, resulting in incompleteness, quality issues, or delays due to significant customization.
The Tenasol Approach: A Medical Record Search Engine
At Tenasol, we’ve built our data platform to be agnostic of any single data format or structure. We expect that data will be inconsistently formatted, and our platform scales to process all data without significant implementation needed to accommodate additional evidence sources. Whether CDA, ADT, images, or FHIR data, our platform operates much more like a medical record search engine, where we crawl the entire contents of a health record, searching for over 4 million codes, terminologies, and health measure evidence sets.
For CDA processing, this means traversing the entire tree, including narrative text, attachments, base-64 encoded data, and parent/child files. Whether processing data from a single EHR or 100 sources simultaneously, the full extract is available on demand and without any one-off implementation or engineering. Recently, our team evaluated several leading CDA to FHIR transformation platforms to compare our solution, and the results were striking. We reviewed two (2) separate examples, each scenario leveraging progressively more complex data to test the limits of existing systems. Using the same de-identified file(s) across each system, Tenasol consistently exceeded performance in terms of information density, conformance, and provenance/traceability.
Sample #1 CDA R2
Tenasol | Vendor 2 | Vendor 3 |
|
| |
Key Findings from Sample 1
Up to 3x Data Captured: During the extraction and conversion process. Tenasol extracted the 79 entities, compared with Vendor 2 (42) and Vendor 3 (23). Vendor 3 demonstrates the most data loss as several concepts were lost in the conversion to FHIR, including: Encounters, Procedures, Medications, and others.
Improved Structure and Validation: Referential integrity is an issue for Vendor 2 as several resources have invalid references to specific resources (e.g., Diagnostic report, practitioner, and patient). Tenasol’s output conforms to the expected FHIR output and passed validation with no issues.
Sample #2: CDA R2, X12, ADT, and PDF Record
Tenasol | Vendor 2 | Vendor 3 |
|
N/A |
N/A
|
Key Findings from Sample 2
(Note: Comparisons for Vendor 2 and 3 were not available as they could not process the input formats in scope. Additionally, we could not identify alternative systems capable of processing this diversity of data for comparison purposes.)
Scalability – Tenasol demonstrated the ability to transform multiple disparate data formats as listed above (ADT, CDA, PDF, X12) from varying EMR/source systems.
Information Gain – In addition to sample 1, a total of 319 concepts were extracted. We now see additional data included in the FHIR bundle, unique to these additional data types, including Claim, Coverage, Device, EOB.
Plug and Play – This output demonstrates the scalability of information extraction leveraging the “search” methodology described above. In addition to supporting multiple input formats, Tenasol’s platform can ingest data from newly available EMRs and perform transformation immediately, without implementation or customization.
Conclusion
Success in the future of data-driven, AI-enabled healthcare requires a true data foundation. As FHIR becomes more ubiquitous, data transformation capabilities will prove to be a critical component of the interoperability stack. As we’ve seen from the examples above, stakeholders should carefully consider whether legacy approaches to enabling this transformation are well-suited to support their long-term data strategy.
Poor Program Performance: Omitting critical evidence, in the FHIR transformation process, including Medications, Procedures, Conditions, and other items, can greatly impact performance on critical quality measures (e.g., COL, BCS), prior authorization decision accuracy, and more.
Data quality monitoring: elevating data quality is only possible when systems are capable of fully analyzing its contents. By fully extracting all data during the conversion process, you can begin evaluating structure, duplication, and terminology (among other things) in real time and build data quality performance incentives into your interoperability agreements.
Compliance Mitigation: Operating on incomplete or missing data exposes organizations to audit and compliance risk. Ensuring full traceability, including context for extracted data and provenance to link source data, and minimizing audit risk
As we’ve seen, healthcare stakeholders should carefully consider whether legacy approaches to enabling this transformation are well-suited to support their long-term data strategy for today and beyond. At Tenasol, complete data extraction powers our platform, unlocking the full potential of your most valuable and useful asset – your data.




GET STARTED NOW
Leverage the Power of AI with Tenasol Today!

Powered by AI,
Purpose Built for Healthcare

Contact Information
2461 Eisenhower Avenue, 2nd Floor
Alexandria, VA 22314
Phone: (202) 888-1757
© 2026 Tenasol. All rights reserved.



Disclaimer:
The information and materials on this website are provided for general informational purposes only and are subject to change without notice. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability of the website or its content. Any reliance you place on such information is strictly at your own risk. We are not responsible for, and do not necessarily endorse, the content of any third-party websites linked from this site. All product names, logos, and brands are property of their respective owners.
Powered by AI,
Purpose Built for Healthcare
Contact Information
2461 Eisenhower Avenue, 2nd Floor
Alexandria, VA 22314
Phone: (202) 888-1757
© 2026 Tenasol. All rights reserved.
Disclaimer:
The information and materials on this website are provided for general informational purposes only and are subject to change without notice. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability of the website or its content. Any reliance you place on such information is strictly at your own risk. We are not responsible for, and do not necessarily endorse, the content of any third-party websites linked from this site. All product names, logos, and brands are property of their respective owners.
Powered by AI,
Purpose Built for Healthcare
Contact Information
2461 Eisenhower Avenue, 2nd Floor
Alexandria, VA 22314
Phone: (202) 888-1757
© 2026 Tenasol. All rights reserved.
Disclaimer:
The information and materials on this website are provided for general informational purposes only and are subject to change without notice. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability of the website or its content. Any reliance you place on such information is strictly at your own risk. We are not responsible for, and do not necessarily endorse, the content of any third-party websites linked from this site. All product names, logos, and brands are property of their respective owners.