Complexities of Processing Modern Health Data
The healthcare industry's journey towards digitization has been marked by significant milestones, each aimed at improving patient care, enhancing operational efficiencies, and ensuring the seamless exchange of health information. However, this evolution has also introduced complexities, especially concerning medical record types, interoperability, and mediums of transfer. This blog explores these challenges, sharing a brief history of interoperability and shedding light on the intricacies of modern healthcare data management and the quest for a more connected and efficient healthcare system.
In The Beginning…
Access to medical records are vital to numerous processes within healthcare and beyond, yet acquiring this information has been notoriously difficult. Prior to the 2000’s much of this difficulty could be traced to the fact that most medical documentation was paper-based and handwritten. This resulted in issues ranging from, information loss, poor searchability, lack of documentation standardization, medical errors and more. Beyond claims data, health data interoperability generally didn’t exist as patients and providers struggled to access information via fax, or worse mail or CD. The Health Information Technology for Economic and Clinical Health (HITECH) Act of 2009 was highly successful at addressing many of these issues by incentivizing provider EMR adoption as evidenced by data from Office of the National Coordinator (ONC):
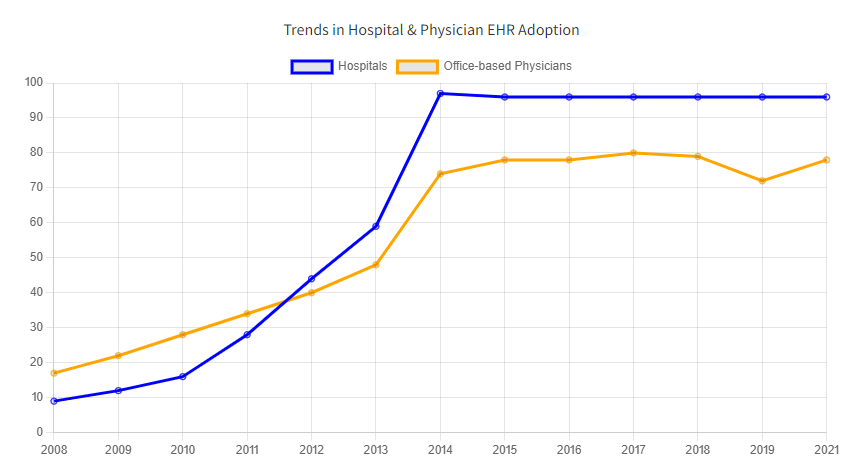
Trends in Hospital & Physician EHR Adoption [1]
As EMR systems proliferated, regional and state data exchanges were established to address the limitations of paper records and fax-based information exchange. Meaningful Use regulations were leveraged to incentivize exchange among providers (e.g. transitions of care) using certified technology. Federal agencies such as VA, DoD and SSA led the way by demonstrating that exchange on a national level was possible and even created open-source reference implementations that the private sector benefitted from. eHealthExchange (formerly NwHIN) was established as a method for RHIOs, state HIEs and health systems to exchange nationally, attracting participants like Epic and others. Competing EHRs established Commonwell Health Alliance, followed by Carequality and others, and interoperability took off.
As data exchange grew, health plans and other non-treatment users were eager to participate, but quickly realized this infrastructure and trust framework was really intended for treatment use-cases. Individual Health IT vendors and EHRs filled the gap, and data exchange continued to expand, but in a fragmented and more proprietary way. The industry split with national networks largely supporting treatment, while other use-cases required a more direct B2B engagement model with proprietary networks and health IT vendors. This approach worked for many, but not all vendors offered such data exchange services and significant gaps in interoperability persisted. More recent federal policies aimed at Consumer Access APIs and TEFCA have sought to address the challenge of scaling data-exchange beyond treatment use-case, but with limited success.
Data Processing in the Era of Multiple Formats
I think all in our industry can agree that achieving interoperability has been an uphill battle. For health plans and other non-treatment use-cases, even the most connected data exchange participants acquire 10% - 40% of the data they need via interoperability. The rest happens through less efficient methods, collecting data manually and employing a mix of vendor solutions. This multi-channel approach complicates backend data processing even further, introducing multiple structured formats in addition to unstructured data from legacy manual collection processes.

The health data industry generally views medical records through the paradigm of “structured” and “unstructured”, the former representing data retrieved through interoperability and the latter represents a catch-all for everything else. The pursuit of structured data is the gold-standard due to its perceived completeness, standardization and ease of processing and information extraction. Additionally structured data is generally available in real-time, a vitally important feature in healthcare. Given that medical records can contain literally millions of codified medical terminologies, organizing this information in a predictable and repeatable way is helpful to clinicians and engineers alike. While all of this is true, there is much more complexity beyond these benefits. Even structured formats, such as CDA and FHIR, can represent data in a variety of unstructured ways, including narrative text, unstructured attachments and base64 encoded information. Unstructured information can make up 80% of a medical record in some cases, and contain terminologies, assessments, findings, conditions and other health evidences in non-standard and uncoded formats that are difficult to extract through automation. The most widely used data platforms struggle to manage this level of complexity, leading many to simply render the entire package as an Image or PDF to simplify processing or for manual review, losing the value of structured data in the process.
The Role of Standards
Often, the health IT industry’s response to improving the state of healthcare data is through the standards development process. Generally driven by organizations like HL7 and various other public/private workgroups, they organize broad stakeholder groups to establish consensus and define minimum requirements for health data. Early examples of standards development in action include HL7 v2/3 messaging and CDA, while more recent standards have focused on FHIR R4. Once a base standard is developed, industry workgroups, generally organized by use-case or domain, adopts it in the form of an implementation guide or specification. Examples of these include, USCDI v3, TEFCA, DaVinci, Gravity Project, and others.

While standards are an important aspect of improving health data, at times their impact can be misplaced and overstated within Health IT for the following reasons:
Without federal mandates or operational implementation, impact of new standards can be muted. Take FHIR for example, which has been the focus of industry workgroups and federal rulemaking over the past 7 years, still pales in comparison to the production use and scale of CDA for medical record data exchange use-cases.
Standards are also designed for flexibility to make implementation more scalable, resulting in wide variations across EHR and network implementations. (if you’ve seen 1 CCD, you’ve seen 1 CCD)
Standards development is notoriously slow, often taking multiple years to reach consensus, followed by lengthy periods of implementation.
Lastly, the increasing volume of standards are making data more complex and difficult to utilize in production. While the old days of fax had numerous inefficiencies, the dataset was simple, consistent and systems could be designed to process it at scale. Interoperability, with its complex formats, wide variation of standards, implementation variability and structures of each standard are a challenge to current systems. Standards alone weren’t meant to solve these issues, rather they highlight the need for more sophisticated systems to process all medical record formats regardless of structure or acquisition method.
AI Enabled Medical Record Processing
As we’ve discussed, there are a confluence of issues that make processing medical data difficult, including:
Availability: Federal policies and interoperability initiatives are making this data more accessible.
Volume: The volume of data is also expanding exponentially due to factors such as health insurance expansion, resulting in more healthcare utilization and documentation than ever before.
Complexity: Increasing number of electronic and structured data formats, including wide variations within them.
Need: Use-cases from quality improvement, risk adjustment, prior authorization, SDoH and more are driving the need to extract more insight from medical record data.
In the era of Health IT dominated by multiple formats for storing and transferring medical records, the healthcare industry faces significant challenges in data processing. Addressing these issues necessitates a unified approach, developing advanced integration tools capable of extracting full value of health data to enhance patient care, deliver better services, create efficiencies, and leverage healthcare data for research and innovation.

By harnessing cutting-edge AI technology, healthcare organizations need solutions that are adept at navigating the complexities of various data formats, ensuring their data systems can efficiently process, store, and transfer patient information regardless of its original format enabling the achievement of a more connected, efficient, and patient-centered healthcare system.